Detecting copied programs - BANDIT
Managing programming laboratories means we have to think about plagiarism. Without
some control, it really does get well out of hand, which ends up being demotivating
for everyone concerned.Over the last few years we have developed a system called
Bandit to cope with this. This collects work submitted by the students
to a laboratory archive, and browses through from time to time looking for copied
code. The archive integrates into our overall laboratory management system - ARCADE
- which means they get warnings about work they have marks for that was not submitted
to the archive; ultimately arcade witholds marks for work that isnt archived.
Keeping the archive record makes it easier for us to track down any missing marks
too.
Bandit analyses code by breaking the submitted program into a
stream of lexical tokens that is independent of the layout of the program,
and such vagaries as comments or the variable names that have been used.
It does this on newly submitted programs and keeps the tokenised representations
of the files. Detecting plagiarism is then a matter of comparing the token
streams of programs and looking for sequences of similar tokens in them,
from which a "similarity" score is assigned to the pair of programs.
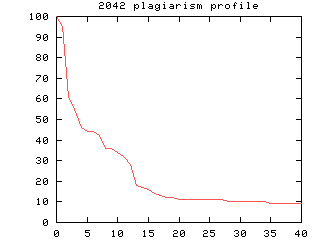
The graph shows the distribution of
plagiarism in one course for the 40 highest scoring program pairs. The
Y-axis is the similarity score. So as we move down the program pairs, we
fall rapidly from a 100% match down to 20% by pair 12. So this course isnt
doing too bad, and we should look closely at those 12 pairs.
Most systems I am aware of then leave you the task of sifting through
the information and looking at the programs by hand to see whether they
are really copies. Bandit comes into its own at this point
as you can see below.
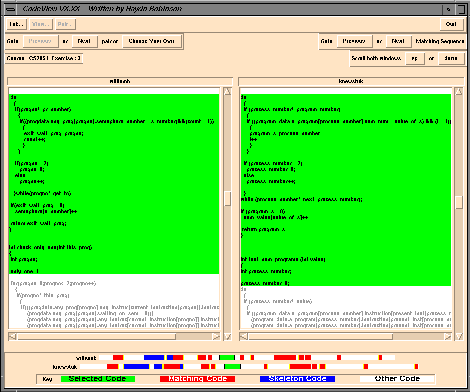 |
|
Color Key |
|
|
|
|
suspect sections of code |
|
|
|
region we are inspecting (suspect) |
|
|
|
code supplied for the exercise |
|
|
|
code not copied |
|
|
We see two programs above. The two coloured bars near the bottom
show an overview map in which red is coppied
work, and on the main screens we are looking at a particular region of
suspect code. This makes it very easy to look at the programs Bandit
brings to your attention and see what exactly is going on. It also makes
it very easy to present this evidence to the individuals concerned.
It can be interesting seeing the novel ways people use to disguise coppies.
Apart from the obvious white space and formatting conversion, changing
of identifiers etc., - converting "for" loops to "while" is a recent fashion
here.
In order to fool Bandit you would need to rearrange all the tokens
in your program so that no suspicious structural correspondence remained.
It only takes a small region of identical code to stand out, or a lot of
small fragments. You would certainly have to understand a lot about a program
in order to rearrange all the statements in that way and still have it
work! and that would be more effort than writing the program in the first
place, so if someone got past the detector that way then we would have
succeeded in teaching them something about programming!
The next goal is to have Arcade automatically email students as
soon as they submit work that is suspected of being copied. That sounds
implausible, but we think it can be made to work and would cut out the
copying syndrome before it gets started (so less work for all concerned).
There's a short paper on Bandit presented the Computers in Teaching
conference in Dublin in 1995 - pd_paper.pdf.
Credits
The people involved in the plagiarism project over the years are: Malcolm
Shute , Koshor Mistry, Haydn Robinson and Adrian West.

home page