This applies to cvs revision 1.11.17 - the most recent stable release at the time of writing. It should work on other cvs 1.11's too. The development branch exhibits the same problem, but the code organisation is quite different.
If you manage large projects with CVS you may have noticed that creating a branch tag can take a long time - in our extreme cases, upto to an hour. Whilst all other big operations are acceptably a couple of minutes or less. But this is bad because people have to queue up behind the branch tag creation, so their quick operations appear go just as slowly.
Our project repository was just over 1Gbyte of text source, with about 6.5 thousand files and some 40-50 engineers working on it. The branch tagging time is a cause of significant difficulty. Fortunately, as CVS is open ("Free") it was easy to fix.
I'll describe what is happening and how this works. But if you just want the fix then skip to the end.
The first time branch tagging became a real issue for us they were taking over 30minutes to create, 45 or more in some cases. Our fix was to write some perl to cull all history older than three months, but keeping the trunk and some essential development branches. This fixed the problem, but it reappeared quite quickly, as you can see on the graph between days 0 and 60.
The graph shows our cvs performance over a 376 day period. The times for most operations grow linearly with the size of the repository, and the number of symbols in it. Branch tagging (the red line) however has a more interesting characteristic.
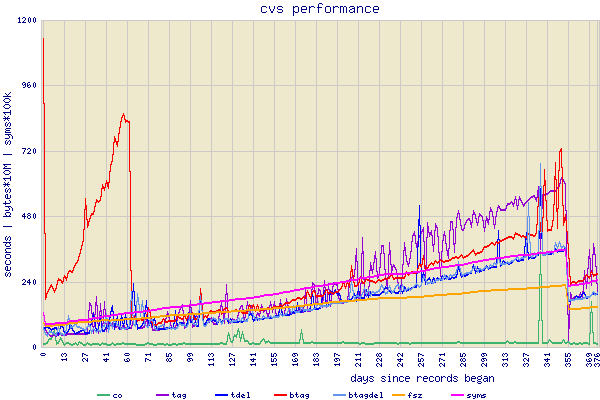
At day 0, branch tag was taking about 19 minutes, which was felt to be too painful, so we again culled all nonessential history, taking branch tagging down to three minutes. But as you can see, it climbed inexorably upward, getting serious again with two months (day 60). The actual characteristic is approximately n**2 against the number of symbols. Time to roll up the sleeves and get into the cvs code - thankful for Free Software. The fix we have gives a more linear characteristic which kept us going to day 355, where we had about 7000 files and approx 25 million symbols in the repository. At that point we culled back again.
The common case for a branch is that most files are never changed on the branch. So overheads are minimized by not really doing anything when a branch tag is created for the project. CVS creates a 'magic' (virtual) branch identified by a branch number of zero, and setting the revision number component to what the branch identifier would be if it really existed. The presence of such an item for a file is saying that the branch has been created, but that no actual changes have been committed to this file for that branch as yet. This is storage, and operation, efficient.
So, when we do a tag -b for a project, CVS creates a magic branch for every file in the project. Unfortunately the algorithm used for that is extremely inefficient. The bulk of its time is taken looking for a free magic branch to use in each file. CVS is nicely modularised, and its lists are kept in hashes maintained by the 'hash' module. You walk the lists by calling 'walklist', supplying a function pointer to apply to each element in the list. For tag -b CVS starts with the lowest revision number, and tries *every* entry in the revision list for the file to see if that has already been allocated. It then bumps the number up, and tries again, until it succeeds. Even if a match is found early on a particular pass, walklist doesn't have an escape mechanism to terminate the walk, so it has to press on with the rest on that pass. That is where the n**2 performance against number of revisions - (revisions roughly proportional to symbols) comes from.
There are two fixes we have done locally to overcome this.
Neither of these changes affect functionality - we have been using this intensively on the 'large' project for about four months now. But as you can see from the graph, it brings branch tagging costs in line with the other cvs operations, so we have happy engineers (well, not actually happy as such, but that is quite a different story outside of the realm of economic and social theories, as conventionally constituted, to address).
I have not submitted this patch to the CVS crew because (a) its not very neat as noted above, and (b) I have seen few other people mention they are having a problem - are large projects rare?
This is for 1.11.17. It's only the server that needs the patch, though it does no harm on clients. The only file changed is src/rcs.c
Copyrights, cautions asto lack of warranty and so forth are, or course, as per the GPL under which CVS is released.